
Während sich der Cortex-M23 und der M33 als Nachfolger für den Cortex-M0+ und den M4 im Markt sukzessive durchsetzen, blieb der Cortex-M55 als erstes Familienmitglied der im Jahr 2019 veröffentlichten Armv8.1-M-Architekturerweiterung beinahe unbeachtet. Mit dem Cortex®-M85 schließt Arm nun diese Lücke nach oben.
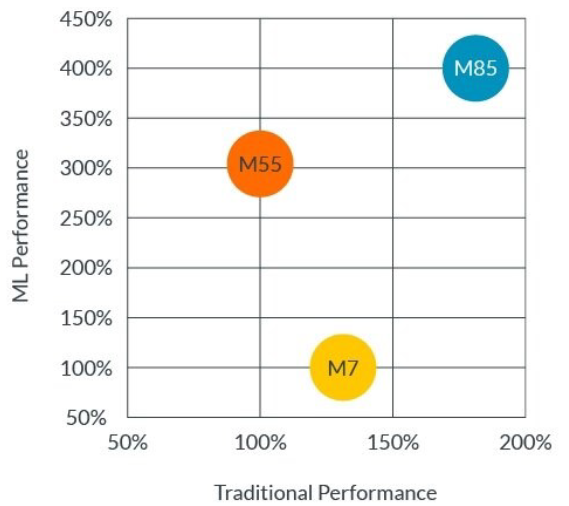
Im Gegensatz zum M55, der speziell auf das Machine Learning (ML)-Marktsegment zugeschnitten ist, gibt es mit dem M85 nun einen echten Nachfolger für den bislang leistungsstärksten M7. Neben den M7-Fähigkeiten deckt der M85 zusätzlich die ML-Fähigkeiten des M55 mit ab und ist damit nicht nur das schnellste, sondern auch das am umfangreichsten einsetzbare neue Familienmitglied.
Die meisten Armv8-M Neuerungen, wie TrustZone, verbesserte MPU und Stack Limits, sind durch den M23 und M33 weitgehend bekannt. Mit der Einführung des M85 werden viele Entwickler aber vermutlich zum ersten Mal mit den über 150 zusätzlichen Befehlen und neuen Features der Armv8.1-M Architektur in Kontakt kommen.
Lohnt sich für mich ein Upgrade vom M7 auf den neuen M85?
Das wichtigste Kriterium zur Beantwortung dieser Frage ist die Abwärtskompatibilität. Die gute Nachricht zuerst: Analog zum Upgrade des M0+ auf den M23 und des M4 auf den M33 gilt dies auch für ein Upgrade des M7 auf den M85. Wer die neuen Features nicht nutzen will, der braucht beim M23, M33 und nun auch beim M85 nur die MPU neu zu programmieren, denn diese ist nicht rückwärtskompatibel.
Wer die neuen Features nutzen möchte, steht zunächst vor der Qual der Wahl. Die Armv8-M und Armv8.1-M Architekturen bieten dem Chipdesigner viele neue Konfigurationsmöglichkeiten. Anwender müssen den neuen Chip sorgfältig anhand der angebotenen Optionen auswählen, um die Wunschfeatures nutzen zu können, die ich im Folgenden kurz beschreibe:
Helium M-Profile Vector Extension (MVE)
Die Anwendung von ML im Edge beinhaltet eine Vielzahl von Matritzenberechnungen in Echtzeit. Die entsprechenden Modelle werden zuvor auf Servern gelernt und mit Toolchains wie z.B. Tensorflow vereinfacht, normiert und mit Hilfe von ML-Bibliotheksfunktionen wie CMSIS-NN auf dem Cortex-M im Edge ausgeführt.
Zur Erhöhung der Berechnungsgeschwindigkeit normiert man die Daten im Modell ohne substantiellen Qualitätsverlust auf möglichst kleine Festkomma- oder Integerformate mit 8 Bit, 16 Bit oder 32 Bit. Die Verarbeitungsgeschwindigkeit des Cortex-M für diese Matritzenberechnungen gehen daher direkt in die ML-Performance ein.
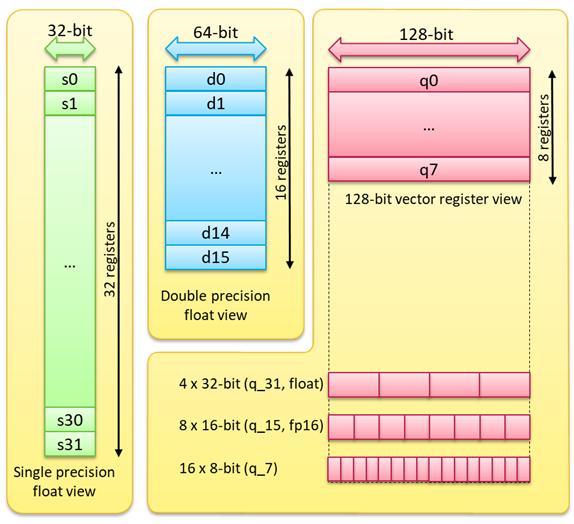
Die Helium-Erweiterung nutzt die Floating Point Unit (FPU)-Register als 128-Bit Vektor-Register und kann dadurch 16 Mal 8-Bit-, 8 Mal 16-Bit- oder 4 Mal 32-Bit-Operationen parallel ausführen. Die Implementierung der CMSIS-NN-Bibliothek sorgt dafür, die nötigen neuen MVE-Befehle des Cortex-M85 einzusetzen. Mithilfe der MVE schafft der M85 im ML eine bis zu 4-fache Performance im Vergleich zu einem M7.
Low Overhead Branch Extension
Nicht nur im ML-Kontext hat die Verarbeitungsgeschwindigkeit von Schleifen einen ausschlaggebenden Einfluss auf die Performance. Daher können im M85 Schleifenkonstrukte durch neue Maschinenbefehle und erweiterte Pipelinefunktionalität fast ohne den üblichen Overhead verarbeitet werden. Mithilfe der neuen Befehle WLS, DLS und LE merkt sich die Pipeline den Beginn und das Ende einer Schleife. Der Schleifenzähler und der Endwert werden in Core-Registern gehalten. Im abgebildeten Beispiel sind das die Register LR und R0. Nur im ersten Schleifendurchlauf werden die im Beispiel rot hinterlegten Schleifenbefehle ausgeführt. Bei allen weiteren Schleifendurchläufen wird nur noch der innere Teil der Schleife wiederholt ausgeführt, im Beispiel grün hinterlegt.

Verglichen mit einer ausgeflachten Schleife werden in Summe nur zwei weitere Befehle benötigt. Sollte während der Schleifenbearbeitung ein Interrupt auftreten, ist nach der Interruptbehandlung eine erneute Ausführung des LoopEnd- (LE) Befehls zur weiteren Aufsynchronisierung der Pipeline nötig; der Overhead hält sich mit einem zusätzlichen Befehl pro Interrupt deutlich in Grenzen. Ein wirklich cooles Feature! Das Schönste ist: Die eigentliche Arbeit, die neuen Befehle zu verwenden, erledigt der Compiler für uns. Die neuen WLS-, DLS- und LE-Befehle und deren Derivate WLSTP, DLSTP, LETP mit Loop Tail Predication sind auch dann im M85 vorhanden, wenn die MVE Helium-Erweiterung nicht implementiert ist.
Half Precision Floating Point
Wie bereits im MVE-Abschnitt beschrieben werden die ML-Berechnung ohne substantiellen Qualitätsverlust auf möglichst kleinen Festkomma- oder Integer-Formaten mit 8-Bit, 16-Bit oder 32-Bit normiert. Daher beherrscht die FPU des M85 nicht nur Single Precision 32-Bit und Double Precision 64-Bit, sondern auch Half Precision 16-Bit Fließkommaoperationen.
PXN-Attribute
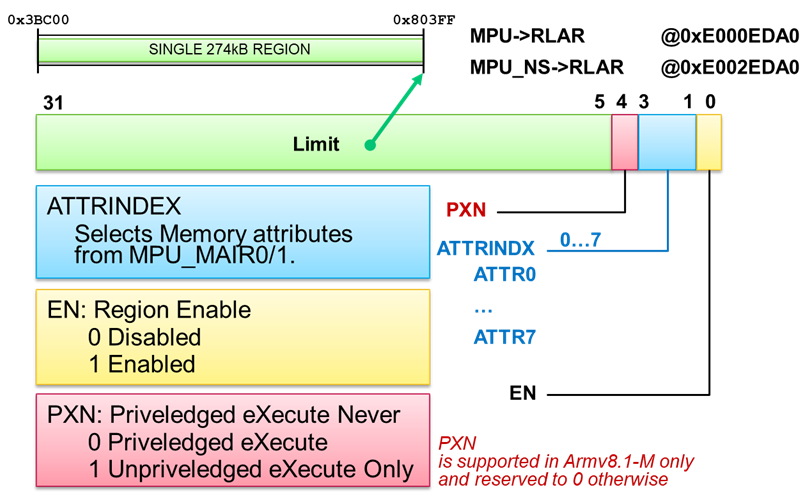
Bei der Verwendung von RTOS-Betriebssystemen laufen die Tasks üblicherweise im nicht-privilegierten User Mode ab. Nur das Betriebssystem selbst und die Interrupt Service Routinen nutzen den privilegierten Mode und erlauben dadurch z.B. den Zugriff auf die Memory Protection Unit (MPU) und den Nested Vectored Interrupt Controller (NVIC). Um das Erschleichen des privilegierten Modus durch Datenmanipulationen auf dem Stack zu verhindern, gibt es in der Armv8.1-M Architektur das neue PXN-Bit in jeder MPU-Region. Damit lässt sich verhindern, dass der User Code der Tasks im privilegierten Mode ausgeführt werden kann; damit wird ein zusätzlicher Riegel vorgeschoben, um unberechtigte Zugriffe auf sicherheitsrelevante Bereiche zu unterbinden.
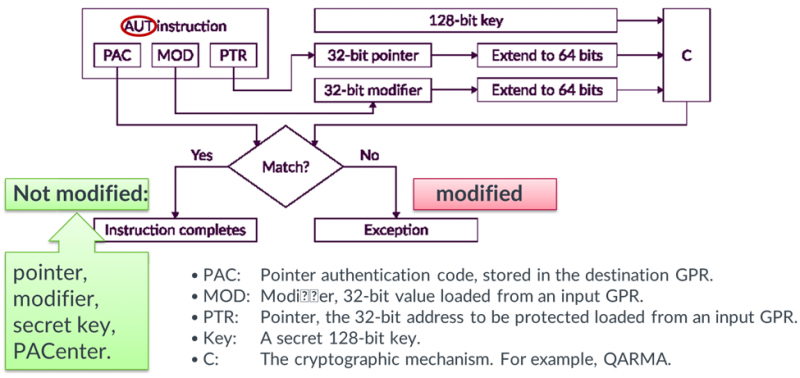
Pointer Authentication und Branch Target Identification (PACBTI)
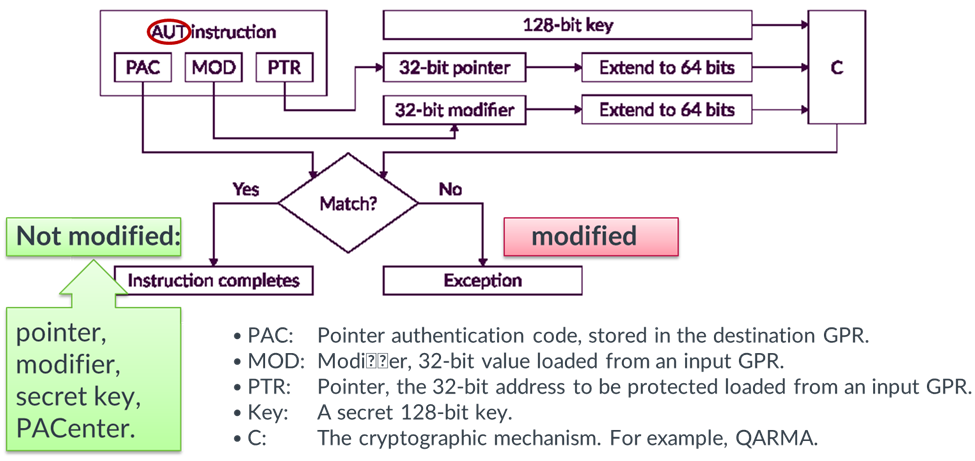
Das mit dem M85 neu eingeführte PACBTI-Feature bietet zusätzlichen Schutz vor potentiellen Zugriffsverletzungen. Das Konzept dahinter ist die Signatur von Pointern und Rücksprungadressen, um deren Manipulation aufdecken zu können und ggf. Gegenmaßnahmen einzuleiten. Mithilfe der PAC-Befehle wird zu Pointern und Rücksprungadressen eine individuelle Signatur erzeugt und intern abgelegt. Diese Signatur kann durch Software nicht gelesen werden.
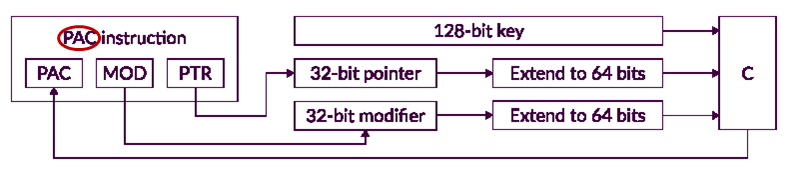
Bei der Nutzung des Pointers oder der Rücksprungadresse wird die Signatur erneut berechnet und intern im Core mit der gespeicherten Signatur verglichen. Eine Abweichung der Signatur wird als Manipulationsversuch gewertet und eine Exception zur Behandlung der Situation ausgelöst.
Ausblick
Die Ankündigung von Renesas, auf der embedded world 2022 eine erste Live-Demo des neues Cortex-M85 RA-Familienmitglieds als Prototyp vorzuführen, lässt die Hoffnung zu, sehr bald erste eigene Erfahrungen mit dem Cortex-M85 Performance-Flaggschiff machen zu dürfen und dabei eventuell Kenntnisse aus den MicroConsult Cortex-M-Trainings im Projektalltag umzusetzen.
Trainings zu den Arm Cortex-Architekturen finden regelmäßig in unserem Schulungszentrum in München sowie Live-Online statt. Jetzt anmelden!
Weiterführende Informationen
MicroConsult Fachwissen zum Thema Mikrocontroller
MicroConsult Training & Coaching zum Thema Mikrocontroller
(Beitragsbild: Renesas Electronics)