

CMSIS, MCAL und Co. – Low-Level-Treiber von der Stange
Embedded-Systeme trifft man heute in vielen Bereichen an. Oft sind sie ein entscheidender Faktor für Komfort, Sicherheit, Nachhaltigkeit und Innovation. Der Anteil der Software in Embedded-Systemen steigt weiter an. Und auch die Hardware, ob Mikroprozessor mit externer Peripherie oder Mikrocontroller, wird immer komplexer. Multicore-Systeme sind bereits Realität, und immer mehr Hersteller bringen neue Multicore-Derivate auf den Markt. Diese komplexe Hardware selbst bis in das letzte Bit zu kennen – und zu programmieren – ist in der dafür zur Verfügung stehenden Zeit nicht mehr möglich. Das macht eine Abstraktion der Hardware unumgänglich.
Für 8-Bit und 16-Bit Mikrocontroller lieferten für gewöhnlich die Hersteller von Bauteilen und Tools die Headerfiles, die Symboldefinitionen für alle Steuer-/Status- und Arbeitsregister der Peripheriemodule enthielten. Nicht selten waren diese Dateien bei 16-Bit Mikrocontrollern schon mehrere tausend Zeilen lang, wie das folgende Beispiel mit insgesamt 12.000 Zeilen zeigt.

Abb. 1 Ausschnitt aus der Datei XE16xREGS.H [1]
Komplexe 32-Bit (Singlecore/Multicore-) Mikrocontroller enthalten Peripheriemodule, bei denen ein einzelnes Modul bereits mehrere hundert Steuer-/Status- und Arbeitsregister zur Verfügung stellt. Dazu gibt es häufig mehrere gleichartige Peripheriemodule in einem Baustein.
Unterschiedliche Bausteinvarianten enthalten oft eine unterschiedliche Anzahl der jeweiligen Peripheriemodule des gleichen Typs. Die Anzahl der Register und der dafür notwendigen Symboldefinitionen wird dadurch immer unübersichtlicher.
Hardware-Abstraktion
Anstelle dieser einzelnen Symboldefinitionen für jedes Peripherieregister kann der komplette Satz an Steuer-/Status- und Arbeitsregistern eines Peripheriemoduls mit Hilfe einer C-Struktur abgebildet werden. Die Register eines Peripheriemoduls liegen hintereinander in einem festgelegten Adressraum – eventuell mit Lücken dazwischen. Die Struktur bildet diese Register in der richtigen Reihenfolge und mit den Lücken ab.
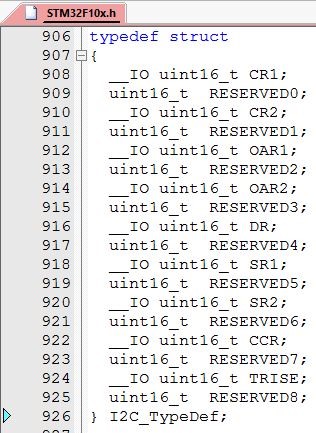
Abb. 2 Struktur für das I2C-Modul eines STM32-Bausteins
Um dieses Abbild der Peripherieregister für mehrere Module des gleichen Typs im Baustein mehrfach wiederverwenden zu können, wird zusätzlich noch die Startadresse des jeweiligen Registerblocks benötigt.
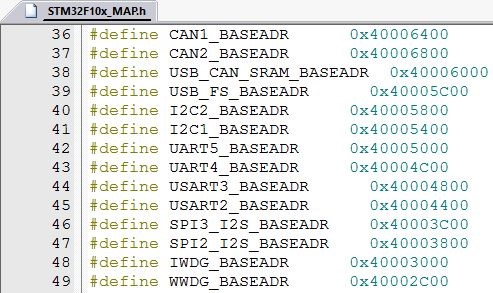
Abb. 3 Basisadressen verschiedener Peripheriemodule eines STM32-Bausteins
Ein Zeiger auf den entsprechenden Strukturtyp wird auf die Basisadresse des Registerblocks gesetzt. Gibt es zwei oder mehr Module des gleichen Typs, gibt es auch zwei oder mehr Zeiger von diesem Typ. Über die Zeiger kann auf alle Elemente der zuvor definierten Struktur (Register des Peripheriemoduls) zugegriffen werden.
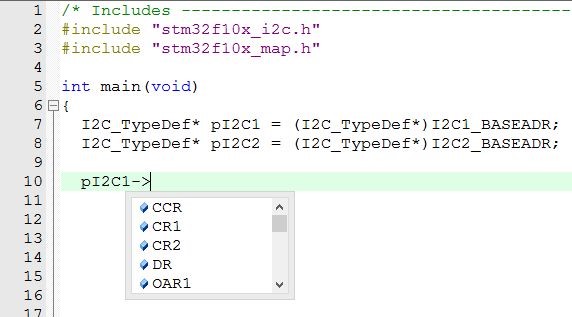
Abb. 4 Zeigerdefinition und Zugriff auf die Register des Typs I2C_TypeDef
In diesem Beispiel wird der Zugriff auf die Peripherieregister direkt in der Applikation durchgeführt. Der Nachteil dieser Art der Nutzung liegt auf der Hand: Jede Änderung und Erweiterung und insbesondere die Wiederverwendbarkeit der Applikation in anderen Systemen ist problematisch, da jede Codezeile in der gesamten Applikation überprüft und unter Umständen angepasst werden muss. Jede Codezeile kann einen Verweis auf Peripherieregister enthalten und muss deshalb für andere Bausteine oder andere Aufgabenstellungen verändert oder entfernt werden.
Der Applikationsprogrammierer muss außerdem wissen, was er mit den Peripherieregistern machen muss oder darf. Jeder lesende oder schreibende Zugriff auf eines der Register erfordert detaillierte Hardwarekenntnisse. Außerdem ist der Testaufwand sehr hoch, weil die gesamte Applikation direkt auf Register des Bausteins zugreift. Wer wann was und wie nutzt, muss bei jeder kleinen Änderung komplett neu getestet werden.
Software-Schichtenmodell
Eine saubere Trennung zwischen Applikationscode und Low-Level-Treibercode dagegen hat viele Vorteile. Es entstehen zunächst unabhängige Software-Schichten (Software Layer – Software-Subsysteme), die über Schnittstellen kommunizieren, und die Subsysteme können getrennt voneinander entwickelt und getestet werden.
Die obere Schicht kann auf die darunterliegende Schicht über eine vordefinierte Schnittstelle (Interface) zugreifen. Dieses Interface ist in der Programmiersprache C nichts anderes als ein Headerfile. Allerdings darf die untere Schicht nicht auch über ein Interface auf die obere Schicht zugreifen, das würde zu bidirektionalen Abhängigkeiten führen. Der Zugriff von unten nach oben kann über Callback realisiert werden. In der Programmiersprache C werden dafür Funktionszeiger verwendet.
Eine Änderung in einem der Subsysteme hat keine Auswirkung auf das andere Subsystem, sofern die Schnittstelle nicht geändert wird.
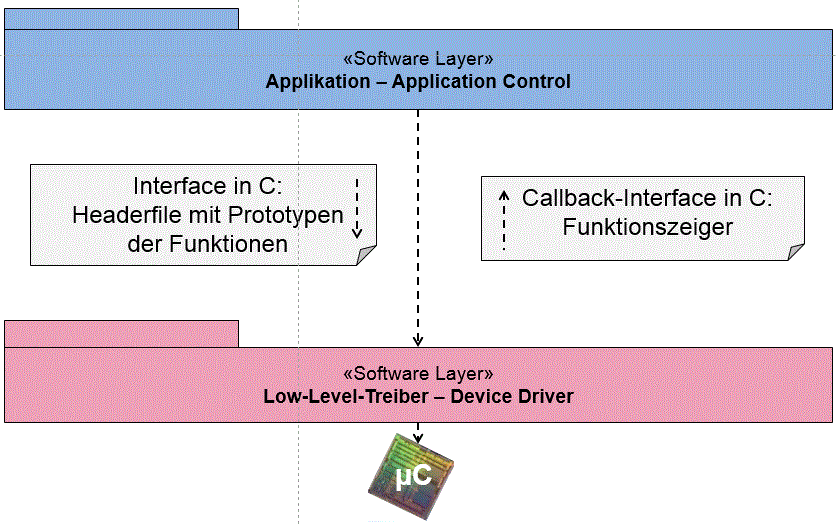
Abb. 5 Software-Schichten-Modell: 2-Schichten-Modell
Aus Sicht der Applikation könnte jetzt der Austausch des Headerfiles und der darunterliegenden Low-Level-Treiberschicht genügen, um bei einem Bausteinwechsel ohne viel Aufwand mit der gleichen Applikation weiterarbeiten zu können. Aber so einfach ist es leider meist nicht. Denn die Namen und die Parameterschnittstellen der Funktionen der Low-Level-Treiberschicht sind oft komplett unterschiedlich definiert. Der Austausch alleine reicht deshalb in den meisten Fällen nicht aus. Alte Funktionsnamen müssen in der Applikation ersetzt, die Übergabeparameterliste für jeden Aufruf überprüft und angepasst werden.
Hat ein anderer Baustein ein spezielles Peripheriemodul vielleicht gar nicht direkt zur Verfügung (z.B. I2C-Modul), muss es durch ein anderes Modul (z.B. SPI-Modul) emuliert werden. Dann müssen ganz andere Funktionen für die Initialisierung und Nutzung dieses Moduls in die Applikation eingebaut werden, und das bedeutet wieder zusätzlichen Zeitaufwand für die Implementierung und den Test.
3-Schichten-Modell mit Low-Level-Treiberabstraktion
Und hier kommt das 3-Schichten-Modell ins Spiel. Zwischen die Low-Level-Treiberschicht und die Applikationsschicht wird noch eine Low-Level-Treiberabstraktionsschicht geschoben. Diese Schicht verbirgt für den Nutzer nach oben (die Applikation) die tatsächlich vorhandene Hardware – also ob zum Beispiel eine echte I2C-Schnittstelle in der Hardware zur Verfügung steht oder ob diese über eine andere serielle Schnittstelle emuliert werden muss.
Die Applikation liefert die Parameter für die richtige Einstellung, die Abstraktionsschicht darunter gibt diese an die passende Low-Level-Treiberkomponente weiter. Natürlich muss bei einem Bausteinwechsel die Abstraktionsschicht entsprechend angepasst werden.
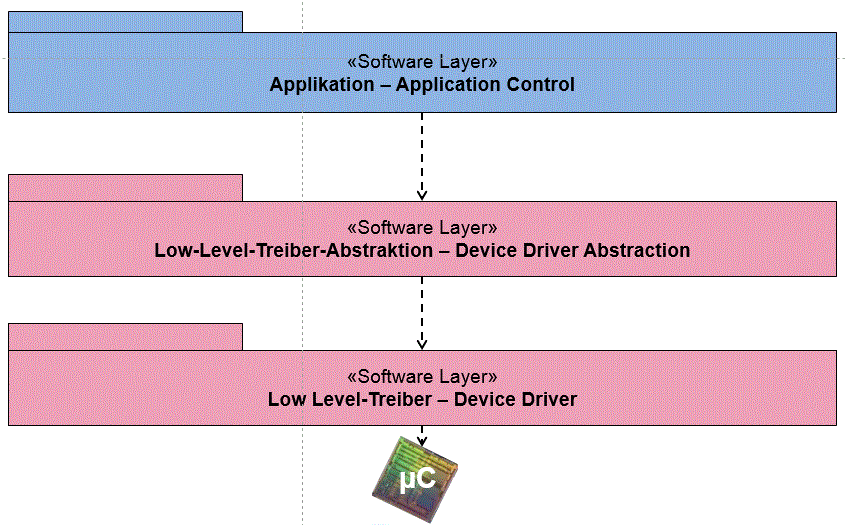
Abb. 6 Software-Schichten-Modell: 3-Schichten-Modell
Selbst schreiben oder fertigen Treiber nutzen?
Aber unabhängig davon ob 2- oder 3-Schichten-Modell, der Low-Level-Treiber wird in jedem Fall benötigt. Und die entscheidende Frage ist jetzt: selbst schreiben oder fertigen Treiber des Bausteinherstellers nutzen?
Selbst schreiben bedeutet, dass es einen „Hardware-Experten“ geben muss, der die Funktionsweise der Peripheriemodule, die Register, die Bitfelder und Bits in den Registern genau kennt und die Initialisierung und Nutzung in die Programmiersprache umsetzt.
Da es keine allgemein gültigen Regeln (Namensregeln, Aufbau der Parameterschnittstelle etc.) gibt, kann die Umsetzung für jeden Baustein oder sogar für jedes Peripheriemodul vollkommen unterschiedlich aussehen, und die Abstraktionsschicht muss jeweils angepasst werden.

Abb. 7 Low-Level-Treiberfunktion mit beliebigem Namen, keine Parameter
Vorteile der „Treiber von der Stange“ nutzen
Werden keine Übergabeparameter an Low-Level-Treiberinitialisierungsfunktionen geliefert, müssen in der Funktion vorgegebene Werte für die Konfiguration verwendet werden. Das schränkt die Wiederverwendbarkeit sehr stark ein, weil für jede Art der Nutzung unterschiedliche Funktionen existieren müssen.
Um den Aufwand an dieser Stelle möglichst klein zu halten, muss es Regeln geben, wie viele und welche Parameter in welcher Reihenfolge an diese Funktionen übergeben werden. Außerdem ist es sinnvoll, die Funktionsnamen immer nach einem fest vorgegebenen Schema aufzubauen. Und das wiederum ist einer der Vorteile bei der Nutzung der „Treiber von der Stange“.
Spezifikationen und Standards erleichtern Portierbarkeit und Wiederverwendbarkeit
Bausteinhersteller und Softwareanbieter schließen sich zusammen und definieren Schnittstellen für den Zugriff auf Peripheriemodule, Echtzeitbetriebssysteme und Middleware-Komponenten. Wird dann ein anderer Bausteintyp der Serie (zum Beispiel ein Cortex-Derivat) eingesetzt, kann die Applikation unverändert bleiben, und die Abstraktion muss nur mit kleineren bausteinspezifischen Anpassungen versehen werden.
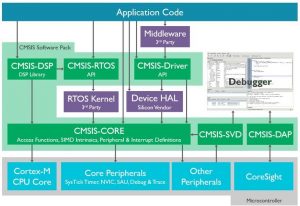
Abb. 8 CMSIS-Schichtenmodell
Die Standardisierung erleichtert also die Portierbarkeit und Wiederverwendbarkeit.
Low-Level-Treiber vereinfachen Nutzung von Ressourcen
Die fertig implementierten Low-Level-Treiber der Bausteinhersteller vereinfachen die Nutzung der Bausteinressourcen. Natürlich muss der Nutzer immer noch wissen, was er mit welchem Baustein realisieren kann. Aber die Details dieser Realisierung, welches Register, Bitfeld oder Bit mit welchem Wert beschrieben werden muss, sind im fertig implementierten Treiber verborgen.
Über eine Initialisierungsstruktur werden einzustellende Parameter an die Initialisierungsfunktion geliefert.

Abb. 9 Initialisierungsstruktur für ein I2C-Modul
Die Applikation füllt die Initialisierungsstruktur mit den einzustellenden Werten und gibt die Basisadresse des zu initialisierenden Moduls und die Adresse der Initialisierungsstruktur an die untere Schicht weiter. Der Aufruf der Low-Level-Treiberfunktion steht im folgenden Beispiel wieder direkt im Applikationscode.

Abb. 10 Initialisierungsstruktur und Aufruf der Initialisierungsfunktion
Hardware Abstraction Layer hilft bei Initialisierung und Nutzung von Peripheriemodul
Die nächste Abstraktionsebene wäre wieder die Trennung von Applikationscode und Low-Level-Treiberzugriffen. Der Applikationsschicht wird vom Hardware Abstraction Layer HAL eine Struktur zur Verfügung gestellt, die alles enthält, was für die Initialisierung und Nutzung eines Peripheriemoduls benötigt wird. Das heißt, neben der Initialisierungsstruktur werden weitere Strukturen, von denen eine beispielsweise Funktionszeiger enthält, in die in der unteren Schicht die tatsächlich benötigten Funktionen des Low-Level-Treiber eingetragen. Die Applikation ruft man über den Funktionszeiger auf und muss nicht mehr wissen, wer sich dahinter verbirgt.

Abb. 11 Applikation mit Hardware Abstraction Layer /HAL-Aufrufen
Im HAL sind drei verschiedene Strukturen definiert. Sie stehen für die Initialisierung (Configuration – cfg), die Steuerung zur Laufzeit (Control – ctrl) und die verschiedenen Funktionsaufrufe (Application Programmers Interface – API) zur Verfügung.

Abb. 12 HAL-Struktur mit Funktionszeigern
Die verschiedenen Strukturen, die für die Nutzung eines Moduls zuständig sind, werden in einer umgebenden Struktur zusammengefasst.

Abb. 13 HAL-Struktur mit Elementen vom Typ Struktur
In kurzer Zeit zum lauffähigen System
Das detaillierte Knowhow steckt also im Low-Level-Treiber. Der Hardware Abstraction Layer verbirgt die Zugriffe auf diese untere Softwareschicht in Strukturen, und die Applikation muss nur noch die Art der Nutzung der Peripheriemodule festlegen.
Darunter wird zwar die Effizienz (Laufzeit, Speicherplatzbedarf) leiden, aber die Wiederverwendbarkeit, Änderbarkeit und Portierbarkeit werden deutlich verbessert. Vor allem bei komplexen Systemen spielt das keine so große Rolle mehr. Vielmehr gilt es, in möglichst kurzer Zeit ein lauffähiges System zu entwickeln. Und dazu tragen fertige Low-Level-Treiber sicherlich bei.
Zusammenfassung
Durch die saubere Trennung der Software in Subsysteme oder Schichten wird die Wiederverwendbarkeit und Austauschbarkeit der Hardware oder der Applikation deutlich verbessert. Die Nutzung fertig implementierter Low-Level-Treiber vereinfacht das Handling komplexer Bausteine. Es spart Zeit sowohl in der Entwicklungsphase als auch in der Vorbereitung bei der Einarbeitung in die Funktionalität des genutzten Bausteins.
Ein Nachteil kann die Komplexität des entstandenen Softwaresystems sein. Speicherbedarf und Laufzeiten verändern sich, deshalb muss in der Analysephase geklärt werden, was für das System wichtiger ist – Effizienz oder Wiederverwendbarkeit, Austauschbarkeit, Anpassbarkeit.
Mehr Information
MicroConsult Training & Coaching zu Embedded- und Echtzeitprogrammierung
MicroConsult Fachwissen Embedded- und Echtzeit-Softwareentwicklung
Abkürzungsverzeichnis
API – Application Programmers Interface
CMSIS – Cortex Microcontroller System Interface Standard
CMSIS-SVD – CMSIS System View Description
DAP – Debug Access Port
DSP – Digital Signal Processing
HAL – Hardware Abstraction Layer
LLD – Low Level Driver
MCAL – Microcontroller Abstraction Layer
RTOS – Real-Time Operating System
Literatur- und Quellenverzeichnis
[1] Infineon XE16x Register Definition File, 28.07.2008
[2] ARM Embedded Software Development (CMSIS)