
While the Cortex-M23 and M33 have gradually gained market acceptance as successors to the Cortex-M0+ and M4, the Cortex-M55, the first member of the Armv8.1 architecture extension released in 2019, went almost unnoticed. With the Cortex®-M85, Arm is now closing this gap at the top end.
Unlike the M55, which is specifically tailored to the machine learning (ML) market segment, the M85 is now a true successor to the previously most powerful M7. In addition to the M7's capabilities, the M85 also covers the ML capabilities of the M55, making it not only the fastest but also the most versatile new member of the family.
Most of the Armv8-M innovations, such as TrustZone, improved MPU, and Stack Limits, are already widely known from the M23 and M33. However, with the introduction of the M85, many developers will likely encounter the additional commands and new features of the Armv8.1-M architecture for the first time.
Is it worth upgrading from the M7 to the new M85?
The most important criterion for answering this question is backward compatibility. The good news first: Just as with the upgrade from the M0+ to the M23 and the M4 to the M33, this also applies to an upgrade from the M7 to the M85. Those who don't want to use the new features only need to reprogram the MPU on the M23, M33, and now also the M85, as it is not backward compatible.
Those wishing to use the new features are initially faced with a difficult choice. The Armv8-M and Armv8.1-M architectures offer chip designers many new configuration options. Users must carefully select the new chips based on the available options to utilize their desired features, which are briefly described below:
Helium M-Profile Vector Extension (MVE)
The application of machine learning at the edge involves a multitude of real-time matrix calculations. The corresponding models are first trained on servers and then simplified and normalized using toolchains such as TensorFlow. Finally, they are executed on the Cortex-M at the edge using machine learning library functions like CMSIS-NN.
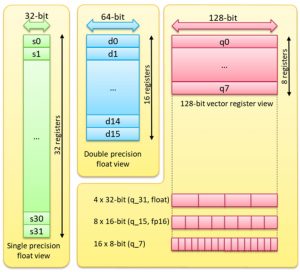
Figure 1: Helium M-Profile Vector Extension (MVE)
To increase computational speed, the data in the model is normalized to the smallest possible fixed-point or integer formats of 8 bits, 16 bits, or 32 bits without substantial loss of quality. The processing speed of the Cortex-M for these matrix calculations therefore directly impacts the machine learning performance.
The Helium extension utilizes the Floating Point Unit (FPU) registers as 128-bit vector registers, enabling it to execute 16 operations of 8 bits each, 8 operations of 16 bits each, or 4 operations of 32 bits each in parallel. The implementation of the CMSIS-NN library ensures the use of the necessary new MVE instructions of the Cortex-M85. With the help of MVE, the M85 achieves up to four times the performance of an M7 in machine learning.
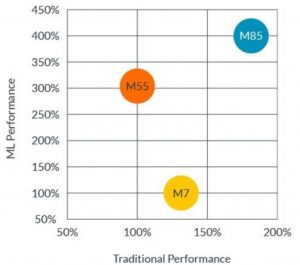
Figure 2: Performance comparison of the M85 with its predecessors
Low Overhead Branch Extension
In the context of machine learning, the processing speed of loops has a crucial impact on performance. Therefore, in the M85, loop constructs can be processed with almost no overhead thanks to new machine instructions and enhanced pipeline functionality. Using the new WLS, DLS, and LE instructions, the pipeline remembers the start and end of a loop. The loop counter and the end value are stored in core registers. Figure 3 shows an example using the LR and R0 registers for this purpose. Only in the first loop iteration are the loop instructions highlighted in red in the example executed. In all subsequent loop iterations, only the inner part of the loop is executed repeatedly, highlighted in green in the example.

Figure 3: Low Overhead Branch Extension
Compared to a flattened loop, only two additional instructions are needed in total. If an interrupt occurs during loop execution, the LoopEnd (LE) instruction must be re-executed after interrupt handling to further synchronize the pipeline; the overhead is significantly reduced to just one additional instruction per interrupt. A really cool feature! The best part is: the compiler does the actual work of using the new instructions for us.

Figure 4: Example Code Low Overhead Branch Extension
Figure 4 shows a simple C code that initializes an array of 256 8-bit values with their respective index.
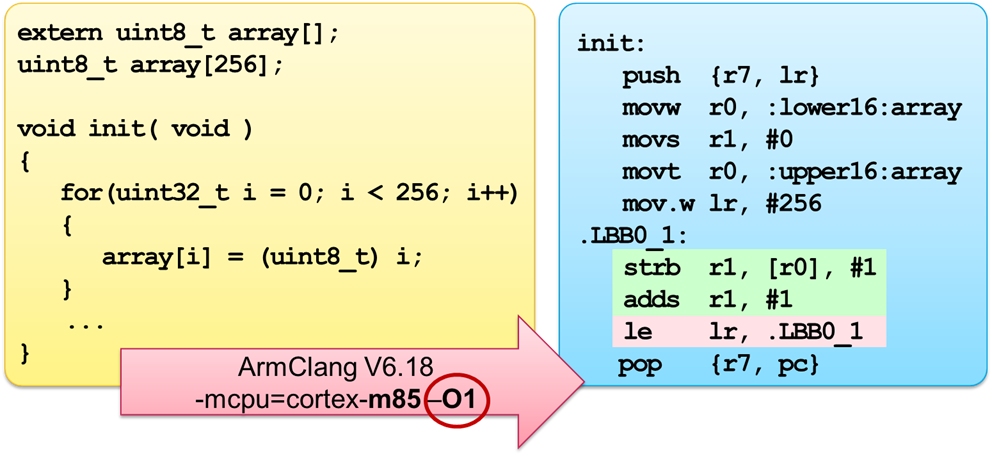
Figure 5: Result of compilation with Optimizer Level 1
In the blue box of image 5, the green and red colors clearly show that the result of the compilation uses the instructions of the Low Overhead Branch Extension, thus reducing the runtime compared to a loop construction with branches.
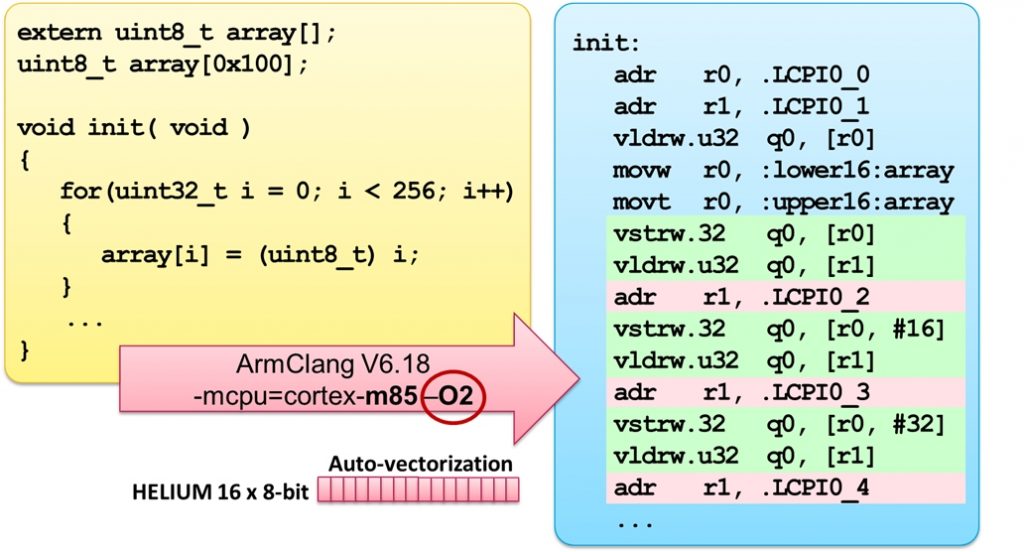
Figure 6: Result of compilation with Optimizer Level 2
In contrast to the result of compilation with optimization level 1, the result with optimization level 2 looks completely different. Figure 6 clearly shows that the Low Overhead Branch Extension is not used here, but rather an optimization called "Auto Vectorization" is used, in which 16 assignments are executed in parallel, employing the MVE Helium extension. The code size increases due to the necessary tables of values, but the runtime is even shorter thanks to the parallelization compared to the result with the Low Overhead Branch Extension.
The new WLS, DLS and LE instructions and their derivatives WLSTP, DLSTP, LETP with Loop Tail Predication are also present in the M85 even if the MVE Helium extension is not implemented.
Half Precision Floating Point
As already described in the MVE section, the ML calculation is normalized to the smallest possible fixed-point or integer formats with 8 bits, 16 bits, or 32 bits without substantial loss of quality. Therefore, the M85's FPU supports not only single-precision 32-bit and double-precision 64-bit operations, but also half-precision 16-bit floating-point operations.
PXN attribute
When using RTOS operating systems, tasks typically run in non-privileged user mode. Only the operating system itself and the interrupt service routines use privileged mode, thereby allowing access to components such as the Memory Protection Unit (MPU) and the Nested Vectored Interrupt Controller (NVIC). To prevent the unauthorized access to privileged mode through stack manipulation, the Armv8.1-M architecture includes a new PXN bit in each MPU region. This prevents the user code of tasks from executing in privileged mode, thus providing an additional safeguard against unauthorized access to security-relevant areas.
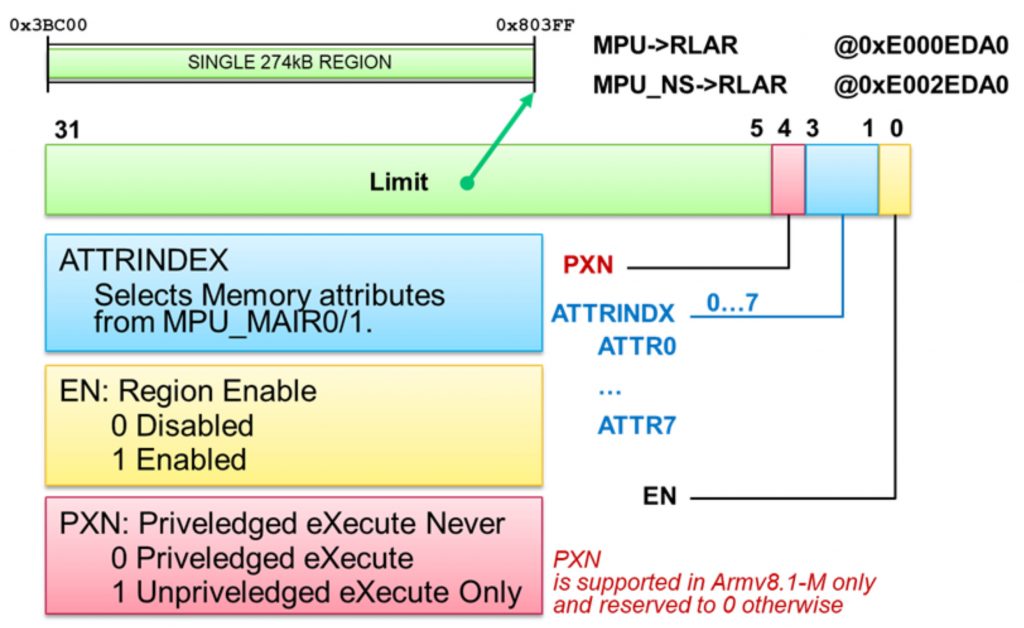
Figure 7: PXN attribute in the MPU
Pointer Authentication and Branch Target Identification (PACBTI)
The PACBTI feature, newly introduced with the M85, offers additional protection against potential access violations. The underlying concept is the signature of pointers and return addresses to detect any manipulation and, if necessary, initiate countermeasures. Using PAC commands, an individual signature is generated for each pointer and return address and stored internally. This signature cannot be read by software.
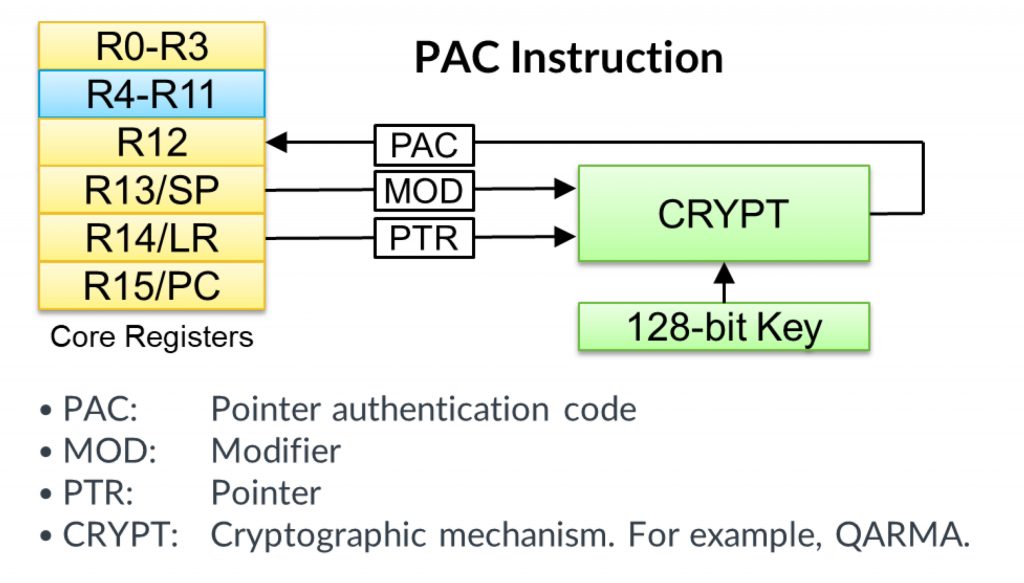
Figure 8: Signature generation with PACBTI
When using the pointer or return address, the signature is recalculated and compared internally in the core with the stored signature. A deviation in the signature is interpreted as a manipulation attempt, and an exception is raised to handle the situation.
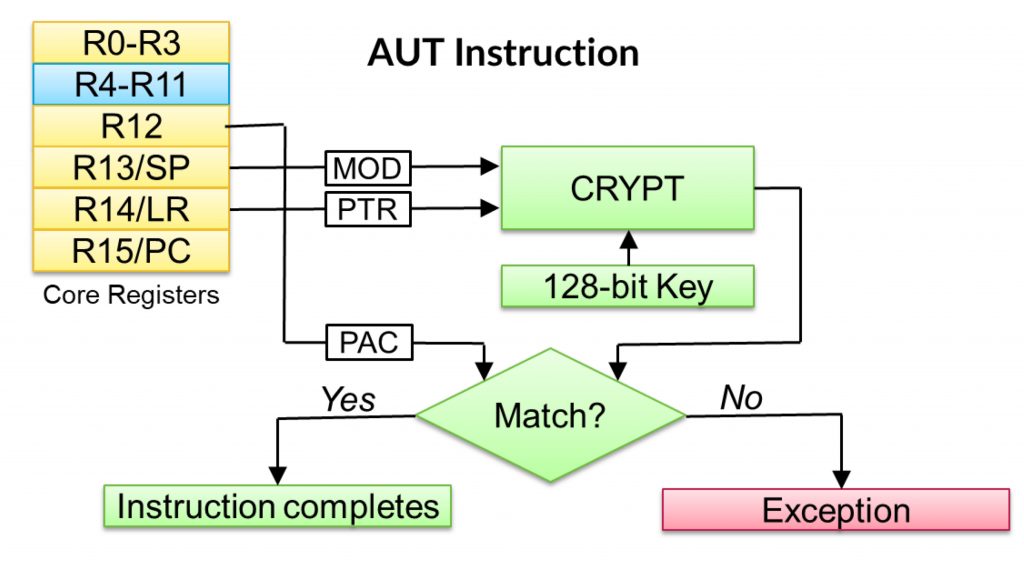
Figure 9: Signature verification using PACBTI
outlook
The first Cortex-M85 chips are expected to appear on the market next year; only then will it be possible to gain firsthand experience with the Cortex-M85 performance flagship.
MicroConsult specializes in training, further education, and consulting for manufacturers of embedded systems. We would be pleased to support you with advice and practical assistance on your journey to implementing new technologies.
Training to the arm cortex architectures They take place regularly at our training center in Munich as well as live online. Register now!
Further information
MicroConsult expertise on the topic of microcontrollers
MicroConsult Training & Coaching on the topic of microcontrollers
