

Die Qualität der Software ist nicht in allen Projekten ideal. Der Einsatz von Software Engineering soll den Code in all seinen Aspekten verbessern. Mit diesen fünf Prinzipien kommen Sie dem Ziel näher. Denn guter Code motiviert!
Immer wieder hört man Aussage wie: „Warum sollte ich überhaupt guten Code schreiben? Interessiert doch eh keinen. Hauptsache, das Projekt ist abgeschlossen!“. Ein großer Teil der Programmierer gibt sich mit schlechtem Quellcode zufrieden – ganz nach dem Motto: „Was willst Du denn, es läuft doch?!“
Doch der Preis von schlechtem Code ist hoch:
- Hoher Wartungsaufwand
- Hohe Kosten für die Weiterentwicklung
- Aufwändige Fehlersuche
Die interne Qualität des Codes trägt also langfristig zu einer Reduzierung der Gesamtkosten bei.
Warum ist guter Code noch wichtig?
- Code schreiben ist ein relativ kleiner Teil der Softwareentwicklung. Etwa 80% der Kosten entfallen auf die anschließende Wartung.
- Es wird wenig neuer Code geschrieben. Die hauptsächliche Arbeit besteht aus Änderungen. Der größte Anteil an der Arbeit ist nicht das Codieren, sondern das Verstehen (Lesen) von Code.
- Fehlerbehebungen in unverständlichem Code erzeugen schnell neue Fehler.
- Wenn am Anfang des Projektes auf Kosten der Codequalität Zeit gespart wird, wird dies am Ende des Projektes ein Vielfaches der eingesparten Zeit kosten.
Prinzipiell ist jedem (erfahrenen) Entwickler bekannt, dass schlechter Code die Arbeit behindert. Allerdings passiert es immer wieder, dass aufgrund von hohem Druck chaotischer Code geschrieben wird, damit Termine eingehalten werden können.
Doch das funktioniert nicht. Der schlechte Code führt dazu, dass die Arbeit langsamer vorangeht und Termine nicht eingehalten werden. Es gibt nur einen Weg: von Anfang sauberen Code schreiben!
Was ist sauberer Code?
- Sauberer Code ist leichter lesbar.
- Andere Entwickler können ihn besser lesen und verstehen.
- Klassen und Methoden sind auf die Erfüllung einer Aufgabe ausgerichtet und werden nicht durch Nebenaufgaben „verunreinigt“.
- Die Abhängigkeiten zu anderem Code sind auf ein Minimum begrenzt.
- Sauberer Code ist gut zu testen.
- Es gibt keine Duplizierungen.
- Der Code enthält keine Überraschungen.
Guter Code motiviert
- Alle Beteiligten sind stolz auf ihre Arbeit.
- Das Programmieren macht mehr Spaß.
- Der Code enthält weniger Fehler.
- Guter Code ist einfacher zu testen.
Für den Mitarbeiter im Projekt heißt das: Guter Code reduziert unangenehme Arbeit.
Die Checkliste für sauberen Code
Um die Erstellung guten Codes zu erleichtern, wurden mehrere Prinzipien für die Softwareentwicklung formuliert. Diese können als eine Art Checkliste gesehen werden, die in der täglichen Arbeit des Entwicklers als Hilfe dienen, die eigene Arbeit zu reflektieren bzw. von vornherein Fehler und kritische Konstrukte zu vermeiden.
Prominente Vertreter solcher Prinzipien sind die SOLID-Prinzipien. SOLID wurde von Robert C. Martin geprägt. Es ist ein Akronym und steht für:
- Single-Responsibility-Prinzip
- Open-Closed-Prinzip
- Liskovsches Substitutionsprinzip
- Interface-Segregation-Prinzip
- Dependency-Inversion-Prinzip
Wenn diese Prinzipien eingehalten werden, entsteht besserer Code, und die Software wird besser wartbar.
Das Single-Responsibility-Prinzip
Das Single-Responsibility-Prinzip besagt, dass eine Klasse nur eine Verantwortlichkeit haben soll. Änderungen an der Funktionalität sollen nur Auswirkungen auf wenige Klassen haben. Je mehr Code geändert werden muss, desto höher ist das Fehlerrisiko.
Hält man sich nicht an dieses Prinzip, verursacht das zu viele Abhängigkeiten und hohe Vernetzung. Das ist wie im wirklichen Leben: Ab einer bestimmten Größe wird ein Universalwerkzeug unhandlich.
Wie kann erkannt werden, ob die Klasse mehr als eine Aufgabe erfüllt?
Die Klasse darf nur einen Grund zur Änderung haben. Wenn sich zwei Anforderungen ändern, darf nur eine davon eine Auswirkung auf die Klasse haben. Hat die Klasse mehrere Änderungsgründe, erfüllt sie zu viele Aufgaben.
Es ist also besser, viele kleine Klassen zu haben als wenige große.
Der Code wird dadurch nicht umfangreicher – er wird nur anders organisiert. Analogie aus dem Bastelkeller: Wenn alle Schrauben in einer Kiste liegen, ist es schwer, die Richtige zu finden. Sind sie gut sortiert auf mehrere Schachteln verteilt, geht das Suchen viel schneller. Genauso verhält es sich mit den Klassen.
Das Open-Closed-Prinzip
Nach dem Open-Closed-Prinzip soll eine Klasse offen für Erweiterungen, aber geschlossen gegenüber Modifikationen sein. Das Verhalten einer Klasse darf erweitert, aber nicht verändert werden. Dieses Prinzip hilft, Fehler in schon fertigen Codeteilen zu vermeiden. Wenn eine Erweiterung nur durch Änderungen innerhalb einer Klasse erreicht werden kann, ist die Gefahr sehr groß, dass durch die Änderung schon fertig implementierte Funktionen neue Fehler bekommen.
Das Open-Closed-Prinzip lässt sich normalerweise über zwei Wege erreichen:
- Vererbung
- Einsatz von Interfaces
Durch Einhalten dieses Prinzips können einer Applikation neue Funktionen hinzugefügt werden, ohne bestehende Klassen zu verändern.
Schon in der (nicht objektorientierten) C-Bibliothek finden sich Beispiele für dieses Prinzip, z.B. die Implementierung der Quick-Sort-Funktion:
void qsort(void *base, size_t num, size_t size, int (*comparer)(void *element1, void *element2));
Um einen eigenen Datentypen sortieren zu können, muss nicht die qsort-Funktion umgeschrieben werden. Der Algorithmus bleibt immer gleich. Der Anwender muss dem Algorithmus lediglich seine eigene Vergleichsfunktion übergeben. Damit wird eine Erweiterbarkeit erreicht, ohne den Algorithmus verändern zu müssen.
Das Liskovsche Substitutionsprinzip
Das Liskovsche Substitutionsprinzip fordert, dass abgeleitete Klassen immer anstelle ihrer Basisklasse einsetzbar sein müssen. Subtypen müssen sich so verhalten wie ihr Basistyp. Das klingt selbstverständlich, aber ist es das auch? Der Compiler weiß, dass eine abgeleitete Klasse auch vom Typ der Basisklasse ist – also immer in diese konvertiert werden kann. Ist das ausreichend? Das Liskovsche Substitutionsprinzip geht weiter als der Compiler.
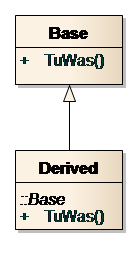
Bild 1: Liskovsches Substitutionsprinzip
Wenn eine Methode einen Parameter vom Typ Base (aus Bild 1) erwartet, z.B. public void TuWasTolles(Base b), darf es keinen Unterschied machen, ob ein Objekt vom Typ Base oder vom abgeleiteten Typ Derived übergeben wird. In der Klasse Derived muss sichergestellt werden, dass das Verhalten aus Sicht der Methode TuWasTolles() identisch ist wie bei der Klasse Base.
Wenn z.B. die Methode der Basisklasse keine Exceptions wirft, darf auch die Methode der abgeleiteten Klasse keine Exceptions werfen. Eine abgeleitete Klasse darf ihre Basisklasse erweitern, aber nicht einschränken oder verändern. Leider wird dieses Prinzip oft missachtet. Unit-Tests können sicherstellen, dass nicht versehentlich ein Verstoß gegen das Liskovsche Substitutionsprinzip in die Software eingebaut wird.
Das Interface-Segregation-Prinzip
Das Interface-Segregation-Prinzip besagt, dass ein Client nicht von den Funktionen eines Servers abhängig sein darf, die er gar nicht benötigt. Ein Interface darf demnach nur die Funktionen enthalten, die auch wirklich eng zusammengehören. Die Problematik ist, dass durch „fette“ Interfaces Kopplungen zwischen den ansonsten unabhängigen Clients entstehen.
Wird ein Aspekt des Interfaces verändert, hat das Auswirkung auf alle Clients – selbst wenn sie diesen Aspekt nicht nutzen. Ein anschauliches Beispiel liefert hier die AWT-Bibliothek von Java: Soll lediglich auf das Ereignis zum Schließen des Fensters reagiert werden, müssen alle Methoden des Interfaces WindowListener implementiert werden (Bild 2).

Bild 2: WindowListener
Was kann getan werden, wenn so ein Interface vorliegt und nicht geändert werden kann? Es kann ein Adapter eingesetzt werden (Adapter-Entwurfsmuster). Dieser Adapter implementiert alle Methoden des Interfaces mit einer Dummy-Implementierung und stellt diese virtuell zur Verfügung. Auch hier dient die AWT-Bibliothek von Java als Beispiel. Diese stellt solch einen Adapter für das vorher gezeigte Beispiel bereit.

Bild 3: Adapter
Das Dependency-Inversion-Prinzip
Das Dependency-Inversion-Prinzip besagt, dass Klassen auf einem höheren Abstraktionslevel nicht von Klassen auf einem niedrigen Abstraktionslevel abhängig sein sollen. Dabei geht es nicht darum, die Abhängigkeiten einfach umzudrehen. Abhängigkeiten zwischen Klassen soll es nicht mehr geben; es sollen nur noch Abhängigkeiten zu Interfaces bestehen (beidseitig). Interfaces sollen nicht von Details abhängig sein, sondern Details von Interfaces. Beispiel: Die Klassen in Bild 4 sind zu stark miteinander verkoppelt.
Die Abhängigkeiten sind so stark, dass ohne Codeänderungen der separate Test einer Klasse nicht möglich ist. Auch Änderungen in den Anforderungen sind durch diese starke Kopplung schwerer umzusetzen.

Bild 4: Starke Kopplung
Lösungsvorschlag 1: Konstruktor-Parameter
Aggregation wird durch Assoziation ersetzt und die Abhängigkeit von einer speziellen Klasse in die Abhängigkeit zu einem Interface geändert (Bild 5). Das konkrete Objekt (der Klasse Logger) wird als Parameter an den Konstruktor der Klasse Bank übergeben. Das ist eine sehr einfache, aber nur bedingt flexible Lösung.
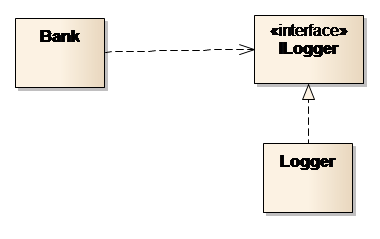
Bild 5: Schwache Kopplung durch Assoziation
Lösungsvorschlag 2: IoC-Container (IoC: Inversion of Control)
Aggregation wird durch Assoziation ersetzt und die Abhängigkeit von einer speziellen Klasse in die Abhängigkeit zu einem Interface geändert. Die konkrete Implementierung registriert sich beim IoC-Container (Bild 6). Der Nutzer (die Klasse Bank) fragt im IoC-Container nach einer Implementierung des benutzten Interfaces (hier ILogger).
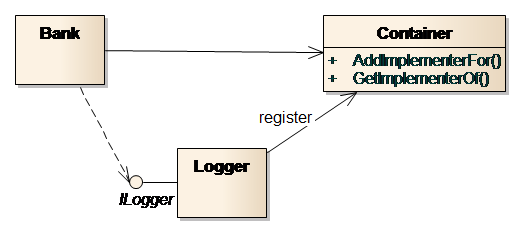
Bild 6: Nutzung eines IoC-Containers
Fazit
Es gibt immer eine Ausrede, warum man gerade keinen guten Code schreiben kann. Doch es wird immer nur eine Ausrede bleiben – einen triftigen Grund, schlechten Code zu schreiben, gibt es nicht.
Die hier gezeigten Prinzipien sind Hinweise, die es einem Entwickler erleichtern, im Alltag die Codequalität zu verbessern. Die (kleine) Mühe amortisiert sich sehr schnell. Änderungen werden einfacher, und auch Test und Fehlersuche werden beschleunigt.
Im MicroConsult Seminar zum Thema Clean Code lernen Sie die wichtigsten Prinzipien, Regeln und Praktiken für die Erstellung von praxisgerechter, wartbarer Softwaren nach den Ideen des „Clean Code“ kennen. Mithilfe von Refactoring können Sie die Codestruktur optimieren und die Komplexität Ihrer Software senken. Damit verbessern Sie die Qualität von vorhandenem Quellcode und sichern von Anfang an die Qualität neuer Software-Projekte. Jetzt anmelden!
Weiterführende Informationen
MicroConsult Training: Clean Code für C-Programme
MicroConsult Training & Coaching zum Thema Softwarequalität
MicroConsult Fachwissen zum Thema Softwarequalität
MicroConsult Training & Coaching zu Embedded-Programmierung
MicroConsult Fachwissen zu Embedded-Softwareentwicklung
Quellen
Robert C. Martin, „Clean Code – Refactoring, Patterns, Testen und Techniken für sauberen Code“